偏差(E)和偏差变化率(EC)是PID问题的基础。
每一次过程采样,都会产生一对E和EC值。
每个E或EC值,都可以被规范成一个标准范围内的值,比如从-3到+3之间。
这个范围又细分为6个区间,每个区间都有一对首尾节点,(-3~-2)、(-2~-1)、(-1~0)、(0~+1)、(+1~+2)、(+2~+3)。
规范化的E或EC值一定会落入这六个区间中的某一个。
为什么要选择从-3到+3做为标准范围呢?这七个数字代表了,我们自然常见的对事物变化的主观评价的七种情况。
没有变化(0,符号表达ZE,Zero)
正向的很小变化(+1,符号表达PS,Positive Small)
负向的很小变化(-1,符号表达NS,Negative Small)
正向的中等变化(+2,符号表达PM,Positive Medium)
负向的中等变化(-2,符号表达NM,Negative Medium)
正向的很大变化(+3,符号表达PL,Positive Large)
负向的很大变化(-3,符号表达NL,Negative Large)
过程值落入这个标准范围,就是对过程变化进行标准化的评价。
在落入的区间中,E或EC的值可能距离首节点比较近,也可能距离尾节点比较近。根据距离远近,可以分别得出与首尾节点的关联度(通常叫隶属度)。隶属度代表数值出现在该点的概率。
这样一来,数值就被描述成了空间的属性,而变化的数值也就成了空间属性的变化。这实际是把关注点从数值本身转向了数值所处的空间。空间成了问题的本质,具体数值只是空间的瞬态。
E和EC是问题的两个维度,它们各对应一个标准范围,各有七个节点的隶属度描述。
两个标准范围结合在一起,就成了一个有49个节点交叉的二维空间。数学上这个二维空间用一个表格也就是二维数组来表达。每个交叉点代表对应的两个维度的相应节点的隶属度都为1的场景,这表示当前的过程值刚刚好好发生在这个交叉点上,没有偏差。
这个二维空间包含了49个这样的标准节点场景,显然这些场景是不可能同时出现的。
这个二维空间的每个维度用一组现实的E和EC的7个节点隶属度分布去填充,就会得到过程真实场景的分布画像。
每个维度的七个节点中,最多只可能有两个节点的隶属度不为零,且相加得1,其它节点的隶属度都为零。
那么在二维场景中,碰巧了也许正好有一个标准场景的概率为1(交叉点对应的E和EC的节点隶属度相乘)会发生,而其它场景的概率都为0,这种可能性极低。绝大多数情况下,E和EC每个维度的隶属度描述会出现2个不为0的节点隶属度,相应的在二维空间中,会形成4种标准场景的概率组合。
对于这个二维表格的49种标准场景,在表格的每个交叉点上给出一个数值。这个数值代表了该处的标准场景概率为1时候的标准对策数值。在场景概率组合的情况下,显然这个数值不会被100%采用。
这个被填充了标准对策数值的二维表格,被称为规则表。PID有三个参数,就需要三个规则表来描述各自的对策。下面是3个具体规则表。
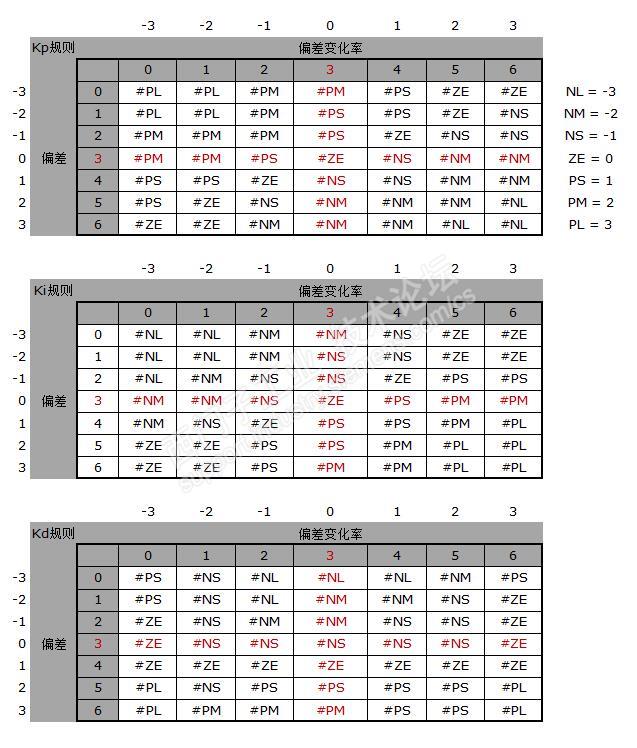
那么做为最终结果的对策数值,也就是按照4种标准场景的概率组合,对4个对策数值进行加权平均的结果。其实说成是全部49种场景的加权合成也行,因为其它项的结果都只能为0。
这里面的权重就是每个标准场景的概率。这就是用现实去过滤策略的理论值,或者说把规则映射到现实场景。
最后在每个算法周期的上升沿,用最终结果去增量式调整PID参数。
这样的模糊逻辑,与PID控制程序链接,就会产生自适应的效果。


----------------------------------------------------------
模糊控制的本质在于找到合适的策略表达方式,让具体的场景能够与之匹配。
它的应用远远不止PID这个二维空间的问题,这也是它能引起我兴趣的原因。
这种控制方式很简单易用,不需要数学模型。是一种非常通用的方式。
把它做为自动工具来观察和总结一个具体过程的特点,也许比直接应用更有意义。
网上对模糊控制的解释,普遍都是就数学形式照葫芦画瓢。纯度不够就不能极致抽象,而抽象的尽头就是回归接地气,质朴化,直觉化。









 首页
首页 智能小西-自动预约
智能小西-自动预约
 风驰卡
风驰卡 产品入门
产品入门 售后登记和质保查询
售后登记和质保查询

 ASP工程师验证
ASP工程师验证 ASP公司证书验证
ASP公司证书验证 售后服务常见问题
售后服务常见问题 首页
首页 售前文档(样本、宣传册等)
售前文档(样本、宣传册等)  售后文档(FAQ、手册等)
售后文档(FAQ、手册等) 首页
首页 立即开通1847会员
立即开通1847会员 首页
首页 教室及直播课
教室及直播课 取证训练营
取证训练营 在线自学课
在线自学课 认证证书查询
认证证书查询 培训伙伴验证
培训伙伴验证 首页
首页 最新发帖
最新发帖 精华帖
精华帖 发新帖
发新帖 已解决问题
已解决问题 精华常见问题
精华常见问题 运维工程师专区
运维工程师专区 官方商城
官方商城 西门子中国
西门子中国

 钻石
钻石


 本版热门话题
本版热门话题

 相关推荐
相关推荐 相关帖子推荐
相关帖子推荐



















 短信登录
短信登录
